

Key Features
- Real-time Face Recognition: Identify and label faces in the video stream with bounding boxes
- Audio-Visual Streaming: Simultaneous video and audio capture and streaming
- Hardware Acceleration: Optimized for NVIDIA Jetson platforms with CUDA support
- Easy Integration: Simple Docker-based deployment
- Performance Monitoring: Built-in FPS counter and system metrics
- Configurable devices: Supports multiple camera and microphone configurations
- Direct RTSP streaming: Streams directly to OpenMind’s API without intermediate relay
What is RTSP?
- RTSP (Real Time Streaming Protocol) is a network control protocol designed to manage multimedia streaming sessions.
- It functions as a “remote control” for media servers, establishing and controlling one or more time-synchronized streams of continuous media such as audio and video.
Key characteristics:
- Control Protocol: RTSP manages streaming sessions but does not typically transport the media data itself
- Session Management: Establishes, maintains, and terminates streaming sessions
- Time Synchronization: Coordinates multiple media streams (audio/video) to play in sync
- Network Remote Control: Provides VCR-like commands (play, pause, stop, seek) for media playback over a network
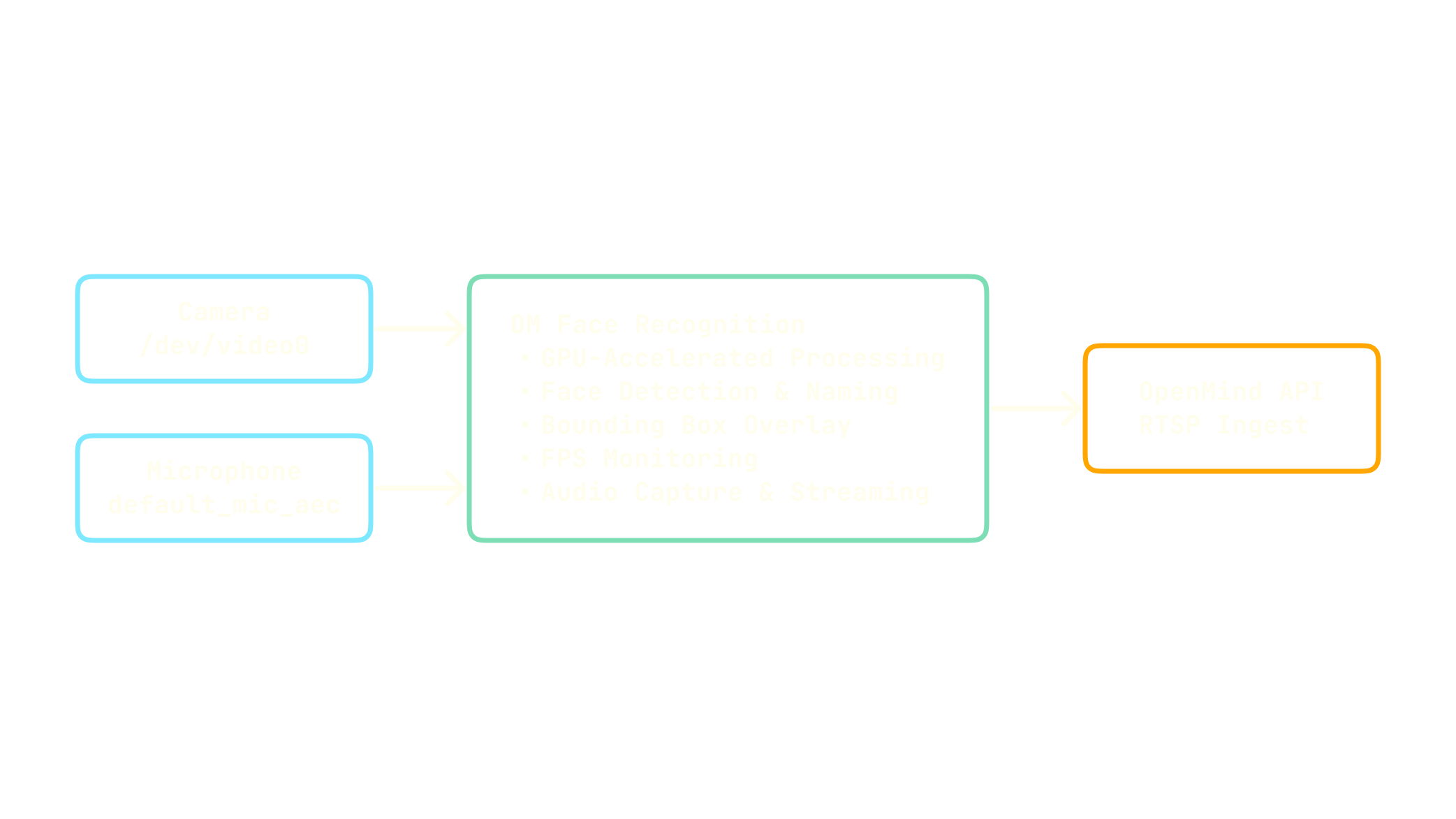
Architecture Diagram
Openmind privacy system
It runs entirely on the robot’s edge device and automatically blurs the faces to prevent any personal information from leaking. Frames never leave the device; only the blurred output is saved or streamed. It works offline and keeps latency low for real-time use.How it works
- Find faces (SCRFD) – Each frame is scanned with the face detector. The model is robust to different angles and lighting. It is optimized with TensorRT, so inference is fast.
- After it locates the face with bounding box, we expand the region around the face bounding box, create a smooth mask, and apply strong Gaussian blur so identity wouldn’t leak or recovered. We prioritize safety and want to protect everyone’s identity – when in doubt (low confidence, motion blur, occlusion), we focus on the side of privacy and blur anyway.
System Requirements
- Docker and docker compose installed
- NVIDIA Jetson device with JetPack 6.1 (or compatible NVIDIA GPU system)
- Access to a video capture device - via USB camera or built in webcam (default: /dev/video0)
- Microphone (for audio streaming - default: default_mic_aec)
- OpenMind API credentials
- Linux system with V4L2 and ALSA support
Installation
-
Clone the repository:
-
Set environment variables:
Get OM_API_KEY and OM_API_KEY_ID from OpenMind portal.
Once you generate a new API key, copy the key and paste it in the OM_API_KEY environment variable.
To get your API key ID, copy the 16 digit id from your API key as highlighted in the image below:
-
Configure your devices (Optional):
-
Ensure devices are accessible
Quick Start
-
Start the streaming service:
-
The system will automatically:
- Initialize the camera and microphone
- Start face recognition processing
- Stream to the configured RTSP endpoint
Configuration
Environment Variables
| Variable | Description | Default |
|---|---|---|
CAMERA_DEVICE | Camera device path | /dev/video0 |
AUDIO_DEVICE | Audio input device | hw:3,0 |
RTSP_URL | RTSP server endpoint | rtsp://your-rtsp-server/stream |
FPS | Target frames per second | 30 |
Configuration
The system is configured the following components:Docker Compose Configuration
The docker-compose.yml file configures:- NVIDIA runtime: GPU acceleration for face recognition processing
- Network mode: Host networking for direct device access
- Privileged mode: Required for camera and audio device access
- Device mapping: Camera (default /dev/video0) and audio (/dev/snd) devices
- Environment variables: OpenMind API credentials, device indices, and PulseAudio configuration
- Shared memory: 4GB allocated for efficient video processing
Processing Pipeline
The streaming pipeline consists of two processes managed by Supervisor:- MediaMTX: RTSP server for stream routing and management
- OM Face Recognition Stream: Main processing service that:
- Captures video from the specified camera device
- Performs real-time face recognition with GPU acceleration
- Overlays bounding boxes, names, and FPS information
- Captures audio from the specified microphone
- Streams directly to OpenMind’s RTSP ingestion endpoint
Environment Variables
We need to configure the following environment variables:- OM_API_KEY_ID: Your OpenMind API key ID (required)
- OM_API_KEY: Your OpenMind API key (required)
- CAMERA_INDEX: Camera device path (default: /dev/video0)
- MICROPHONE_INDEX: Microphone device identifier (default: default_mic_aec)
How It Works
- Video Capture: Captures video from the specified camera device
- Face Processing: Uses AI to detect and recognize faces in real-time
- Audio Capture: Simultaneously records audio from the microphone
- Streaming: Combines video and audio into an RTSP stream
- Monitoring: Provides real-time performance metrics
Ports
The following ports are used internally:- 8554: RTSP (MediaMTX local server)
- 1935: RTMP (MediaMTX local server)
- 8889: HLS (MediaMTX local server)
- 8189: WebRTC (MediaMTX local server)
Development
Build the image:
Customize the processing settings:
To modify the om_face_recog_stream parameters, edit the command in video_processor/supervisord.conf.Troubleshooting
Common Issues
-
No video feed:
- Verify camera device permissions
- Check if the camera is being used by another application
-
Audio not working:
- Verify the correct audio device is specified
- Check PulseAudio configuration
-
Performance issues:
- Ensure hardware acceleration is properly configured
- Reduce resolution or FPS if needed